
What Token Follows (WTF) when generating text with a Large Language Model (LLM)?
This notebook (you can run in Colab) and companion slide deck is my perfunctory (don’t say tokenistic) attempt to demystify GenAI for a general technology audience, specifically: how text is generated by LLMs.
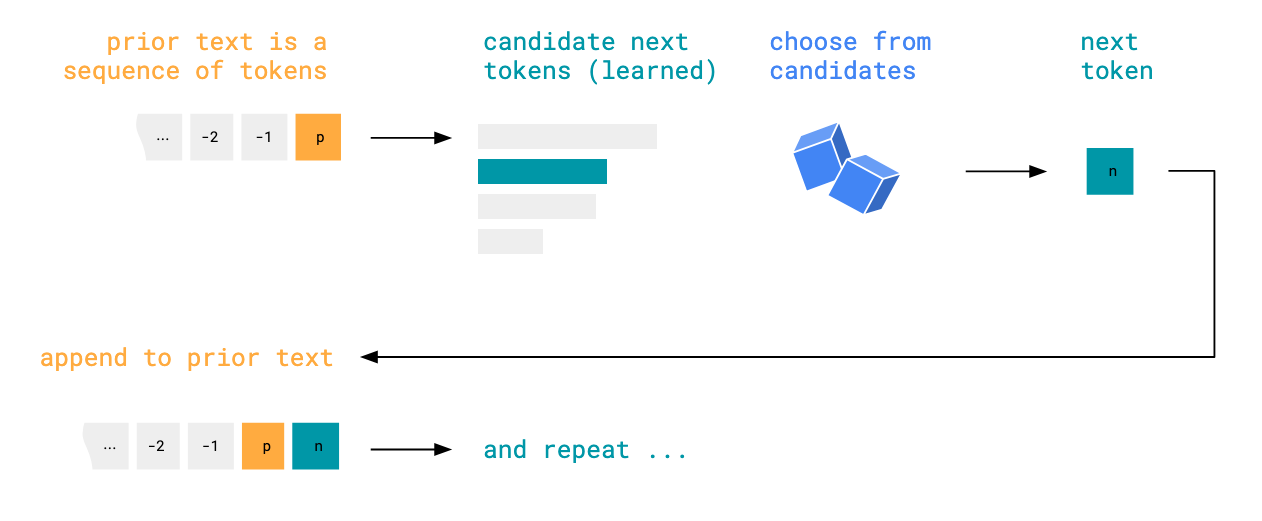
The premise of the notebook is to demonstrate and visualise that the text LLMs output is simply a result of:
- Prior text, including the initial input (prompt) and the text already generated,
- Ranked candidates for the next text fragment (learned in training),
- Choosing from those candidates, and then
- Iterating, with the chosen text fragment appended to the prior text.
A word on tokens
LLMs break text up into tokens, which are the “text fragments” above and can be though of as whole or part words, sometimes including punctuation. Any tokenisation scheme comprises a finite number of distinct tokens, so each can be given an ID. Here are some examples: 4587:" Of" and 11579:"utely". These are tokens used by the partucular LLM we use in the notebook.
Follow the LLM plot
If we prompt our LLM with the sequence of tokens that represents text something like "Human: Tell me a story. Assistant:", we find the following top 10 candidate tokens:
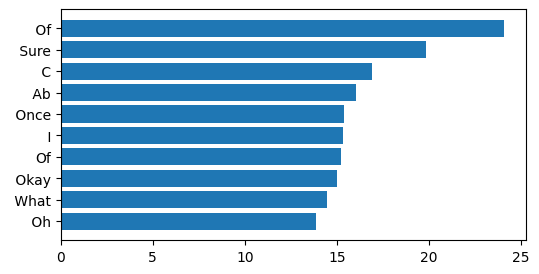
These candidate tokens are ranked and plotted according to the probabilities (as logits) – learned during the LLM training process – that each token would follow the prior sequence of tokens. It’s worth noting that these probabilities don’t change after training, and are now fixed when the LLM is deployed to generate text. So every time we start with this prompt for this LLM, we have the same probability distribution for next tokens.
The first slide in the LLM WTF deck shows how we get a different next token probability distribution each time we append a token to the prior text.
Where the variety emerges, in terms of which token is actually selected next, and after that, and so on, depends on the sampling strategy.
Sampling
Common sampling strategies include:
- Greedy: simply choose the most likely candidate at each point
- Top-K: pick from the k most likely candidates, according to their probabilities (i.e. in repeated trials, you would select more likely candidates more often than less likely candidates). Note k = 1 is the same as greedy.
- Top-P: pick from the set of candidates that collectively exceeds a probability threshold
Greedy is hence deterministic (with minor caveats about computation optimisation). Each time you feed the same prompt into the LLM, you will get the same output, as at each iterative step in generating the output, you’ll choose the same most likely candidate. Greedy is compared to the other strategies below.
Top-K and Top-P will in contrast produce varied answers. This is often described as non-deterministic, but I also like to think of it as an example of sensitive dependence on initial conditions. Even with the outcome of each choice of candidate determined by “random” numbers, we will still generate a deterministic, repeatable sequence of tokens if we use a fixed sequence of “random” numbers, which is common practice for repeatability in ML.
Therefore, repeated generation with the same prompt and either Top-K or Top-P will produce outputs that diverge at some token, and the likelihood of divergence increases the longer the output becomes. The third slide in the LLM WTF deck compares sampling strategies.
Temperature

Top-K and Top-P are both influenced by a parameter called temperature. Higher values of temperature “smooth out” the probability distribution, making it more likely that we select lower ranked candidates at each sampling. Low values have less smoothing effect, down to temperature of 0, which preserves the base distribution.
Therefore, repeated generations with the same prompt are likely to diverge earlier in the output sequence the higher the temperature, which we see in the image above.
Demystified or differently mystified?
I hope the explanation here is reasonably accessible to a general technology audience, despite some specialised terms. One thing you can do to make LLMs seem less magical is to run the notebook on a low powered machine like a regular laptop, and experience the resultant slow trickle of tokens.
The key takeaways in any case:
- LLMs generate text step-by-step, according to the prior text and defined generation functions
- These generation functions are learned during training time and hence fixed at generation time
- Variety in generation is a result of probabilistic sampling strategies, which can be dialled up or down, in the generation functions