
Semantle is an online puzzle game in which you make a series of guesses to discover a secret word. Each guess is scored by how “near” it is to the secret target, providing guidance for subsequent guesses, but that’s all the help you get. Fewer guesses is a better result, but hard to achieve, as the majority of words are not “near” and there are many different ways to get nearer to the target.
You could spend many enjoyable hours trying to solve a puzzle like this, or you could devote that time to puzzling over how a machine might solve it for you…
Scoring system
Awareness of how the nearness score is calculated can inspire potential solutions. The score is based on a machine learning model of language; how frequently words appear in similar contexts. These models convert each word into a unique point in space (also known as an embedding) in such a way that similar words are literally near to one another in this space, and therefore the similarity score is higher for points that are nearer one another.

We can reproduce this similarity score ourselves with a list of English words and a trained machine learning model, even though these models use 100s of dimensions rather than two, as above. Semantle uses the word2vec model but there are also alternatives like USE. Comparing these results to the scores from a Semantle session could guide a machine’s guesses. We might consider this roughly equivalent to our own mental model of the nearness of any pair of words, which we could estimate if we were asked.
Sibling strategies
Two general solution strategies occurred to me to find the target word guided by similarity scores: intersecting cohorts and gradient descent.
Intersecting cohorts: the score for each guess defines a group of candidate words that could be the target (because they have the same similarity with the guessed word as the score calculated from the target). By making different guesses, we get different target cohorts with some common words. These cohort intersections allow us to narrow in on the words most like to be the target, and eventually guess it correctly.

Gradient descent: each guess gives a score, and we look at the difference between scores and where the guesses are located relative to each other to try to identify the “semantic direction” in which the score is improving most quickly. We make our next guess in that direction. This doesn’t always get us closer but eventually leads us to the target.

I think human players tend more towards gradient descent, especially when close to the target, but also use some form of intersecting cohorts to hypothesise potential directions when uncertain. For a machine, gradient descent requires locations in embedding space to be known, while intersecting cohorts only cares about similarity of pairs.
Sympathetic sequences
Semantle is open source and one could create a superhuman solver that takes unfair advantage of knowledge about the scoring system. For instance, 4 significant figures of similarity (as per semantle scores) allows for pretty tight cohorts. Additionally, perfectly recalling large cohorts of 10k similar words at each guess seems unrealistic for people.
I was aiming for something that produced results in roughly the same range as a human and that could also play alongside a human should they want a helpful suggestion. Based on limited experience, the human range seems to be – from exceptional to exasperated – about 20 to 200+ guesses.
This lead to some design intents:
- that the solving agent capabilities were clearly separated from the Semantle scoring system (I would like to use a different semantic model for the agent in future)
- that proposing the next guess and incorporating the results from a guess would be decoupled to allow the agent to play with others
- that the agent capabilities could be [de]tuned if required to adjust performance relative to humans or make its behaviour more interpretable
Solution source
This post shares the source for the gradient descent solver and a simple simulator for semantle scores. Note that the word2vec model data for the simulator (and agent) is available at this word2vec download location.
I have also made a few iterations on the intersecting cohorts approach, which works but isn’t ready for publication.
Seeking the secret summit
The gradient descent (or ascent to a summit) approach works pretty well by just going to the most similar word and moving a random distance in the direction of the steepest known gradient. The nearest not previously guessed word to the resultant point is proposed as the next guess. You can see a gradual but irregular improvement in similarity as it searches.

In the embedding space, I overlaid a network (or graph) of “nodes” representing words and their similarity to the target, and “spokes” representing the direction between nodes and the gradient of similarity in that direction. This network is initialised with a handful of random guesses before the gradient descent begins in earnest. Below I’ve visualised the search in this space with respect to the basis – the top node and spoke with best gradient – of each guess.
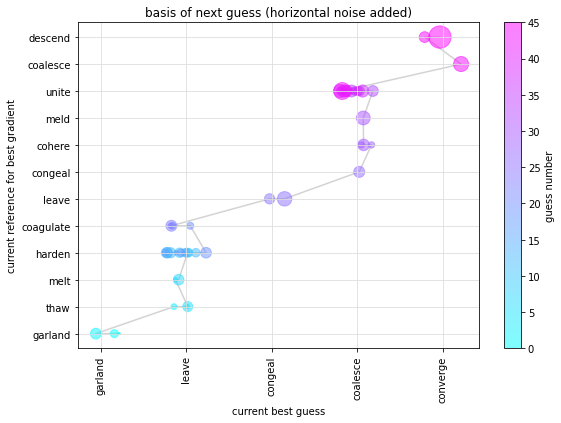
The best results are about 40 guesses and typically under 200, though may blow out on occasion. I haven’t really tried to optimise the search; as above, the first simple idea worked pretty well. To [de]tune or test the robustness of this solution, I’ve considered adding more noise to the search for the nearest word from the extrapolated point, or compromising the recall of nearby words, or substituting a different semantic model. These things might come in future. At this stage I just wanted to share a sketch of the solver rather than a settled solution.
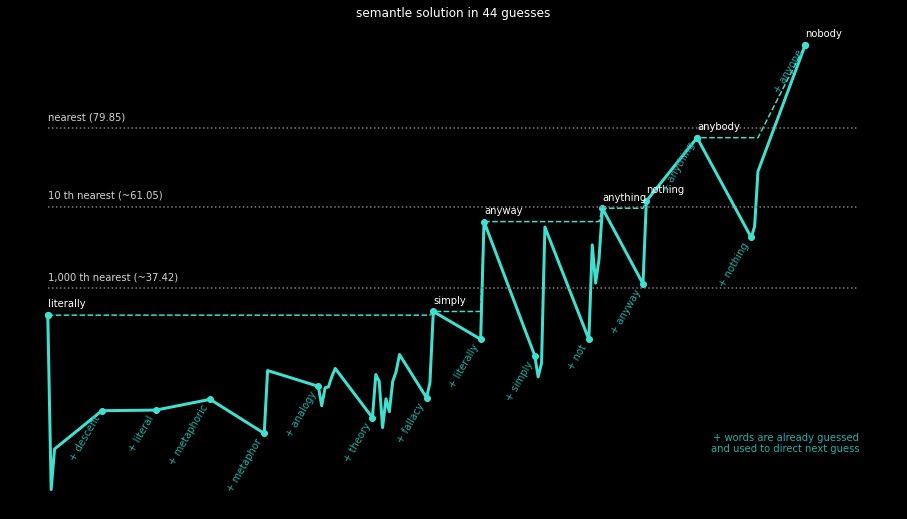
Postscript: after publishing, I played with the search visualisation in an attempt to tell a more intuitive story (from literally to nobody).
Stop the sibilants, s’il vous plaît
C’est suffit! I’m semantically sated. After that sublime string of subheadings, the seed of a supplementary Wordle spin-off sprouts: Alliteratle anyone?