
This is the third post in a series exploring LEGO as a Metaphor for Software Reuse through data (part 1 & part 2).
In this post, we’ll look at reuse through the lens of LEGO® part lifespans. Not how long before the bricks wear out, are chewed by your dog, or squashed painfully underfoot in the dark, but for what period each part is included in sets for sale.
This is a minor diversion from looking further into the reduction in sharing and reuse themes from part 2, but lifespan is a further distinct concept related to reuse, worthy I think of its own post. All the analysis from this post, which uses the the Rebrickable API, is available at https://github.com/safetydave/reuse-metaphor.
Ages in a Sample Set
To understand sets and parts in the Rebrickable API, I first raided our collection of LEGO build instructions for a suitable set to examine, and I came up with 60012-1, LEGO City Coast Guard 4×4.

In the process I discovered parts data contained year_from and year_to attributes, which would enable me to chart the ages of each part in the set when it was released, as a means of understanding reuse.

In line with the exponential increase of new parts we’ve already seen, the most common age bracket is 0-5 years, but a number of parts in this set from 2013 were 50-55 years old when it was released! Let’s see some examples of new and old parts…

The new flipper is pretty cool, but is it even worthy to be moulded from the same ABS plastic as Slope 45° 2 x 2? The sloping brick surely deserves a place in the LEGO Reuse Hall of Fame. It has depth and range – from computer screen in moon base, to nose cone of open wheel racer, to staid roof tile, to minifigure recliner in remote lair. Contemplating this part took me back to my childhood, all those marvellous myriad uses.
And yet I also recalled the slightly unsatisfactory stepped profile that resulted from trying to build a smooth inclined surface with a stack of these parts. As such, this part captures the essence and the paradox of reuse in LEGO products; a single part can do a lot, but it can’t do everything. Let’s look at lifespan of parts more broadly.
Lifespans Across All Parts
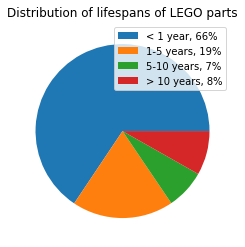
The distribution of lifespan across LEGO parts is very uneven.

The vast majority of parts are in use less than 1 year, and only a small fraction are used for more than 10 years. Note I calculate lifespan = year_to + 1 - year_from, and this is using strict parts data, rather than also including minifigures.
Exponential Decay
This distribution looks like exponential decay. To understand more clearly, it’s back to the logarithmic domain, where we can fit approximations in two regimes; for the first five years (>80% of parts) and then for the remaining life.
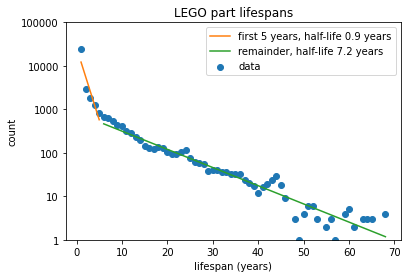
The half-life of parts in the first 5 years is about 1 year over that period. So each of the first five years, only about half the parts live to the next year. However, the first year remains an outlier, as only 34% of parts make it to their second year and beyond. After 5 years, just under 1,000 survive compared to the 25,000 at 1 year, and from that point the half-life extends to about 7 years. So, while some parts like Slope 45° 2 x 2 live long lives, the vast majority are winnowed out much earlier.
Churn
We can also look at the count of parts released (year_from) and the count of parts retired (year_to + 1) each year.
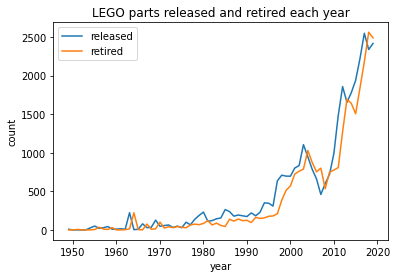
As expected, parts released shows exponential growth, but parts retired also grows, and almost in synchrony, so the net change is small compared to the total parts in and out. By summing up the difference each year, we can chart the number of active parts over time.

Active parts are a small proportion of all parts released to date; they represent about one seventh of all parts released, approximately 5,500 of 36,500. Comparing total changes to the active set size each year also shows a high and increasing rate of churn.

So even as venerable stalwarts such as Slope 45° 2 x 2 persist, in recent years about 80% of active LEGO parts have churned each year! Interestingly, the early 1980s to late 1990s was a period of much lower churn. Note also churn percentages prior to 1970 were high and varied widely (not shown before 1965 for clarity), probably reflective of a much smaller base of parts and maybe artefacts with older data.
Lifespans vs Year Release and Retired
We’ve got a lot of insight from just year_from and year_to. One last way to look at lifespans is how they have changed over time, such as lifespan vs year released or retired.

Obvious in these charts is that we only have partial data on the lifespan of active parts (we don’t know how much longer until they’ll be retired), but as above, they are a small proportion. We can discern a little more by using a box plot.

The plot shows, for each year, median lifespans (orange), the middle range (box), the typical range (whiskers) and lifespan outliers (smoky grey). We see here again that the 1980s and 1990s were a good period in relative terms for releasing long-lived parts that have only just been retired. However, with the huge volume of more short-lived parts being retired in recent years, we don’t see their impact in the late 2010s on the retired plot, except as outliers. In general, the retired (left) plot, like the later years of the released (right) plot shows lower lifespan distributions because the long-lived parts are overwhelmed by ever-increasing numbers of contemporaneous short-lived parts.
Lessons for Software Reuse
If LEGO products are to be a metaphor and baseline for reuse in software products, this analysis of part lifespans is consistent with the observations from part 1, while further highlighting:
- Components that are heavily reused may be a minority of all components, and in an environment of frequent and increasing product releases, many components may have very short lifetimes, driven by acute needs.
- There may be a “great filter” for reuse, such as the one year or five year lifespan for LEGO parts. This may also be interpreted as “use before reuse”, or that components must demonstrate exceptional performance in core functions, or support stable market demands, before wider reuse is viable.
- Our impressions and expectations for reuse of software components may be anchored to particular time periods. We see that the 1980s and 1990s (when there were only ~10% of the LEGO parts released to 2020) were a period of much lower churn and the release of relatively more parts with longer lifespans. The same may be true for periods of software development in an organisation’s history.
- Retirement of old components can be synchronised with introduction of new components, and in fact, this is probably essential to effectively manage complexity and to derive benefits of reuse without the burden of legacy.
Further Analysis
We’ll come back to the reduction in sharing and reuse theme, and find a lot more interesting ways to look at the Rebrickable data in future posts.
LEGO® is a trademark of the LEGO Group of companies which does not sponsor, authorize or endorse this site.