
This is the fifth post in a series exploring LEGO® as a Metaphor for Software Reuse. A key consideration for reuse is the various roles that components can play when combined or re-combined in sets. Below we’ll explore how we can use data about LEGO parts and sets to understand the roles parts play in sets.
I open a number of lines of investigation, but this is just the start, rather than any conclusion, of understanding the roles parts play and how that influences outcomes including reuse. The data comes from the Rebrickable data sets, image content & API and the code is available at https://github.com/safetydave/reuse-metaphor.
Hero Parts
Which parts play the most important roles in sets? Which parts could we least easily substitute from other sets?
We could answer this question in the same way as we determine relevant search results from documents, for instance with a technique called TFIDF (term frequency-inverse document frequency). We can find hero parts in sets with set frequency-inverse part frequency, which in the standard formulation requires a corpus of parts “documents” listing sets “terms” for each set that includes that part, as below.
part 10190: "10403-1 10403-1 10404-1 10404- ... " part 3039: "003-1 003-1 003-1 003-1 021-1 ... " part 3023: "021-1 021-1 021-1 021-1 021-1 ... "
Inverse part frequency is closely related to the inverse of the reuse metric from part 4, hence we can expect it will find the least reused parts. Considering again our sample set 60012-1, LEGO City Coast Guard 4×4, (including 4WD, trailer, dingy, and masked and flippered diver), we find the following “hero” parts.

This makes intuitive sense. These “hero parts” are about delivering on the specific nature of the set. It’s much harder to substitute (or reuse other parts) for these hero parts – you would lose something essential to the set as it is designed. On the other hand, as you might imagine, the least differentiating parts (easiest to substitute or reuse alternatives) overlap significantly with the top parts from part 4. Note while mechanically – in a sense of connecting parts together – it may not be possible to replace these parts, these parts don’t do much to differentiate the set from other sets.

Above, we consider sets as terms (words) in a document for each part. We can also reverse this by considering a set as a document, and included parts as terms in that document. Computing this part frequency-inverse set frequency measure across all parts and sets gives us a sparse matrix.

This can be used as a search engine to find the sets most relevant to particular parts. For instance, if we query the parts "2431 2412b 3023" (you can see these in Recommended Parts below), the top hit is the Marina Bay Sands set, which again makes intuitive sense – all those tiles, plates, and grilles are the essence of the set.
Recommended Parts
Given a group of parts, how might we add to the group for various outcomes including reuse? For instance, if a new set design is missing one part that is commonly included with other parts in that design, could we consider redesigning the set to include that part to promote greater reuse?
A common recommendation technique for data in the shape of our set-part data is Association Rule Learning (aka “Basket Analysis”), which will recommend parts that are usually found together in sets (like items in baskets).
An association rule in this case is an implication of the form {parts} -> {parts}. Multiple of these rules form a directed graph, which we can visualise. I used the Efficient Apriori package to learn rules. In the first pass, this gives us some reasonable-looking recommendations for many of the top parts we saw in part 4.
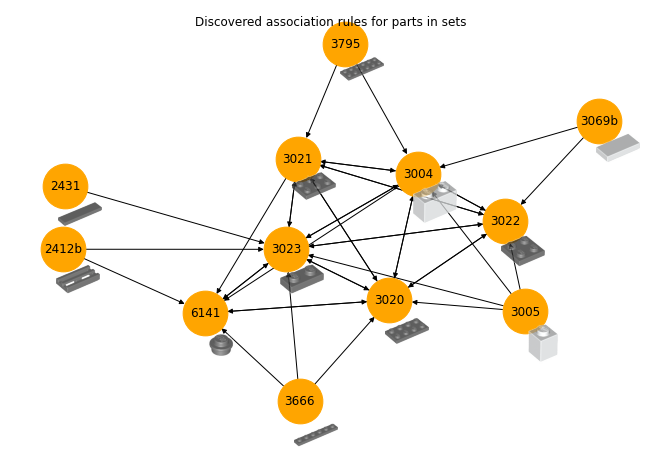
You can read this as the presence of 2431 in a set implies (recommends) the presence of 3023, as does 2412b, which also implies 6141. We already know these top parts occur in many sets, so it’s likely they occur together, but we do see some finer resolution in this view. The association rules for less common parts might also be more insightful; this too may come in a future post.
Relationships Between Parts
How can we discover more relationships between parts that might support better outcomes including reuse?
We can generalise the part reuse analysis from part 4 and the techniques above by capturing the connections between sets and parts as a bipartite graph. The resultant graph contains about 63,000 nodes – representing both parts and sets – and about 633,000 edges – representing instances of parts included in sets. A small fragment of the entire graph, based on the flipper part 10190, the sets that include this part, and all other parts included in these sets, is shown below.


This bipartite representation allows us to find parts related by their inclusion in LEGO sets using a projection, which is a derived graph that only includes parts nodes, linked by edges if they share a set. In this projection, our flipper is directly linked to the 1312 other parts with which it shares any set.

You can see this is a very densely connected set of parts, and more so on the right side, from 12 o’clock around to 6 o’clock. We could create a similar picture for each part, but we can also see the overall picture by plotting degree (number of connections to parts with shared sets) for all parts, with a few familiar examples.

This is the overall picture of immediate neighbours, and it shows the familiar traits of a small number of highly connected parts, and a very long tail of sparsely connected parts. We can also look beyond immediate neighbours to the path(s) through the projection graph between parts that don’t directly share a set, but are connected by common parts that themselves share a set. Below is one of the longest paths, from the flipper 10190 to multiple Duplo parts.

With a projection graph like this, we could infer that parts that are designed to be used together are closer together. We could use this information to compile groups of parts to specific ends. Given some group of parts, we could (1) add “nearby” missing parts to that group to create flexible foundational groups that could be used for many builds, or we could (2) add “distant” parts that could allow us to specialise builds in particular directions that we might not have considered previously. In these cases, “nearby” and “distant” are measured in terms of the path length between parts. There are many other ways we could use this data to understand part roles.
(When I first plotted this, I thought I had made a mistake, but it turns out there are indeed sets including both regular and Duplo parts, in this case this starter kit.)
The analysis above establishes some foundational concepts, but doesn’t give us a lot of new insight into the roles played by parts. The next step I’d like to explore here is clustering and/or embedding the nodes of the part graph, to identify groups of similar parts, which may come in a future post.
Lessons
As I said above, there are no firm conclusions in this post regarding reuse in LEGO or how this might influence our view of and practices around reuse in software. However, if we have data about our software landscape in a similar form to the set-part data we’ve explored here, we might be able to conduct similar analyses to understand the roles that reusable software components play in different products, and, as a result, how to get better outcomes overall from software development.
Coming Next
I think the next post, and it might just be the last in this series, is going to be about extending these views of the relationships between parts and understanding how they might drive or be driven by the increase in variety and specialisation discussed in part 2.
LEGO® is a trademark of the LEGO Group of companies which does not sponsor, authorize or endorse this site.