
AI is full of contradictions: capable but unreliable, local improvements create externalities, generalist models are evaluated against specific criteria, and so on. Antifragility is a framework that deals in contradictions too, and seems an appropriate lens through which to explore AI systems architecture, as I had used it in an earlier era to explore hand-crafted software.
Music:Response
Defining antifragile, our sheet music:
Antifragile is a word coined by [Nicholas Nassim] Taleb to describe things that gain from disorder. Not things that are impervious to disorder; the words for that are robust, or resilient. Of course, things that are harmed by disorder are fragile.
And our canonical response, to play along, Dumbbell Delivery:
… place your bets in one of two places, but not in between. You first ensure that you are protected from catastrophic downside, then expose yourself to a portfolio of potentially large upsides. In such cases, you are antifragile.
If, instead, you spread yourself across the middle of the dumbbell, you carry both unacceptably large downside exposure and insufficiently large upside exposure. In such cases, you are fragile.
Donald Reinertsen makes a similar argument for exploiting the asymmetries of product development payoffs in The Principles of Product Development Flow.
This is also reflected in a diverse portfolio of time-boxed experiments in What to expect when you weren’t expecting an R&D project and discovering product payoffs in No Smooth Path to Good Design.
Skip ahead to the architectural patterns if you like, but I think you’ll get something out of the shared baseline we establish in the intervening sections.
Deterministic and non-deterministic components
Any software system is made up of multiple components. Historically, these were largely deterministic, in that the same inputs were at least intended to produce the same outputs.
Architecting with AI, by which in 2026 I typically mean LLMs and cousins, we deliberately introduce components from which we expect “non-deterministic” behaviour.
Let’s break down a little the history of “non-deterministic”:
- I think in most instances we strictly mean sensitive dependence on initial conditions, rather than non-determinism,
- This includes components with behaviours affected by random numbers in their initial conditions, which have long been part of traditional software. One example is generating desirable variability in games, to maintain an element of surprise.
- But even when we use random numbers, it has also been possible with some engineering effort to track every single instance of a random number, fix the seeds, and reproduce with exactitude long sequences (including of game-play, as we did in our test suite at Immersive Technologies in the early 2000s),
- Engineers and scientists would also use random numbers guide or perturb search strategies such as simulated annealing in optimisation problems, and improve the robustness of proposed solutions to environmental variation. Here the variability is necessary to escape from local minima.
- With the introduction of more Machine Learning (ML) capabilities to software systems through the 2010s, we saw the use of random numbers at training time, including in stochastic gradient descent, a special case of optimisation. These random numbers were frequently controlled, as above, when reproducibility was required.
- We also saw non-deterministic behaviour at ML inference time when making predictions on novel (non-deterministic) data. However, these components were typically defined around a narrow task with explicit inputs and outputs, such as numerical prediction or classification, limiting the scope of non-determinism. See some related posts on evaluating and managing risk in these narrowly-scoped components.
LLMs as non-deterministic components
Now with LLM-powered AI, some things stay the same and some change.
What stays the same is that we can reproduce exactly long sequences if we control all the random inputs. For instance, using the same model, the same input, a greedy sampling strategy and temperature of 0, we would always get the same output (non-deterministic hardware accelerations aside). While this type of test might be part of validating system integration, it unfortunately won’t cover many use cases.
Variability in LLM responses is generally desirable, to maintain an element of user surprise (and hence engagement), if not necessary, to avoid local minima in the LLM’s search through the space of possible responses. LLMs are great at certain types of searches over the response space, like finding a reasonable transformation of some input text under some program defined by natural language.
Two key things I think have changed when it comes to dealing with non-determinism in LLMs are:
- We typically use LLMs primarily at inference time for initially poorly defined problems. As such we haven’t always gone through the rigour of defining success and building a labelled training set, as would be necessary for training an ML model prior to deployment. Therefore, we don’t always know how to evaluate or constrain LLM outputs in early iterations, instead relying on vibes. While LLMs may be highly capable, they are also unreliable, which vibes alone, being subject to confirmation bias, don’t expose, and
- Related to the poor problem definition, the input/output space is orders–if not hundreds of orders–of magnitude bigger than the spaces associated with narrow ML solutions. Both input and output are fundamentally strings of tokens from a very large vocabulary, mapped to high dimensional semantic spaces. This makes the evaluation and safety problem particularly thorny, as between any two known prompts or any two known responses, there’s generally room for unknowns to creep in.
Input/output space of LLMs
It’s worth taking a moment to understand the vastness of the input and output spaces of LLMs, either in the surface form of tokens or the latent semantic space.
“Space,” [the Hitchhiker’s Guide] says, “is big. Really big. You just won’t believe how vastly hugely mind-bogglingly big it is. I mean, you may think it’s a long way down the road to the chemist, but that’s just peanuts to space.
Douglas Adams, The Hitchhiker’s Guide to the Galaxy
Say a typical model has a vocabulary of 100,000 distinct tokens. For every 100 tokens of input or output, there are 100,000^100 or 10^500 possible (though not probable) sequences of tokens. There are only about 10^80 atoms in the universe, or 10^420 times fewer than the sequences of just 100 tokens! The number of dimensions of token space equals the length of the token sequence, with each dimension being able to take on any categorical value from the vocabulary.

Semantic or embedding spaces boast around 1,500 to 3,000 dimensions. Imagine if on your trip to the chemist, instead of 3 choices of direction at every intersection – straight, left and right – you have 3,000 choices! (d0, -d1, +d1, -d2, +d2, …). With this mental picture, you may start to understand why, in high dimensional spaces, every pair of points starts to appear equally distant. An implication of every point appearing equally distant is that there’s always plenty of space for another point in between any two points.
Right, neutral, and harmful answers
The vast size of input and output spaces is relevant to our efforts to evaluate and assure the safety of non-deterministic LLM components. We have effectively endless right answers, and these are driven by effectively endless right questions, if we think about the input space too.
But not every question and answer can be “right”. At the very least, the negatives of the “right” values must be “wrong”, but it’s not a stretch to say there are effectively endless wrong questions and answers too. In any case, there must be some boundaries between the right and wrong.
We should be careful about thinking of those boundaries as smooth though. They will in general be highly jagged, as just one token–”not”, “a”, “un”, “anti”–can make all the difference to the valence of a much longer sequence.
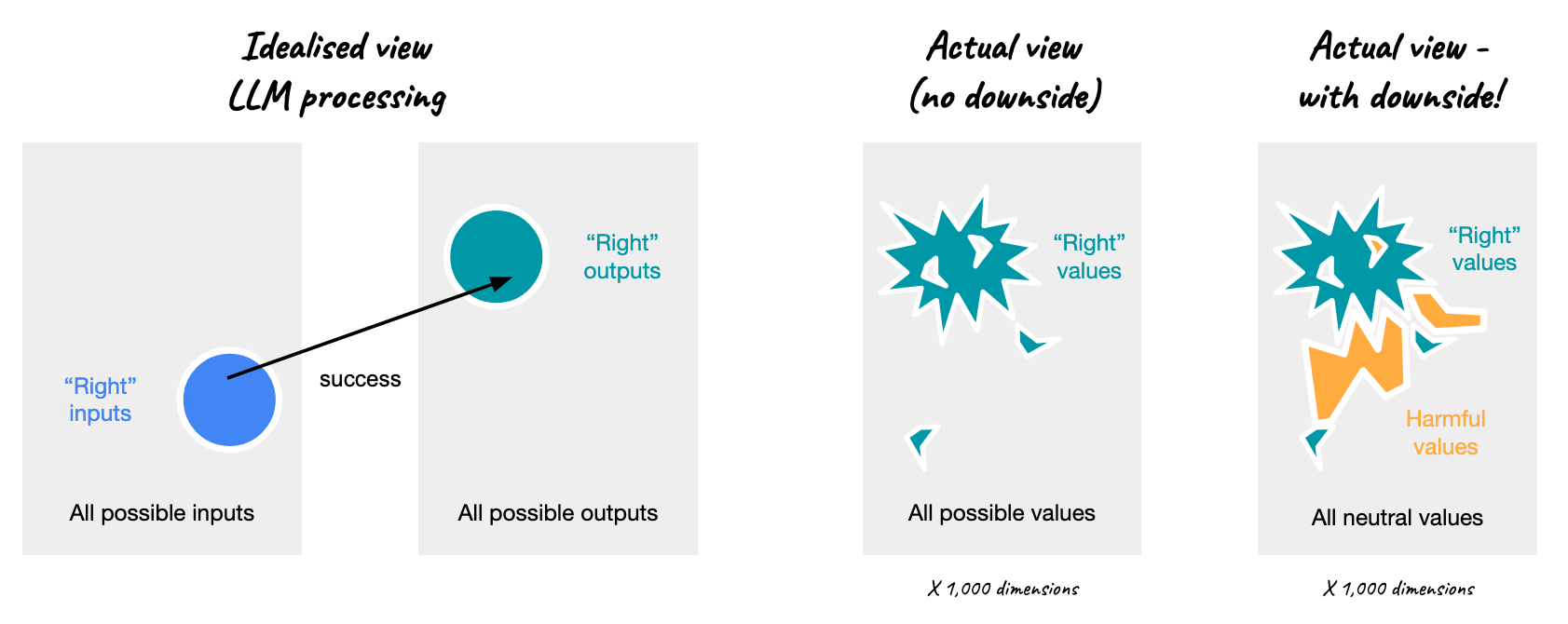
So we have jagged boundaries, but we also have porous boundaries. If any two know points may have unknown points between them, then we conclude that any two right points may have an undiscovered wrong point between then, and any two wrong points may have a right point between them.
It’s also the case though that the wrong answers are not uniformly wrong, but may be further decomposed into neutral and harmful answers. A right answer might be a tasty recipe, and neutral answer a bland dish, and harmful answer fatally poisonous. When LLMs are connected to other systems and resources like financial accounts, a harmful answer can cause very costly actions. These might be thought of as side-effects instead of outputs, but we can reason on outputs for now.
This further distinction is highly relevant to the antifragile perspective, so we should consider:
- Right questions or answers: captures variable upside that may not have been possible otherwise, try to exploit as much as possible,
- Neutral questions or answers: no upside but not catastrophic downside, disregard if volume manageable, and
- Harmful questions or answers: catastrophic failure, avoid any exposure.
Anitfragile also differentiates between risk and exposure. Risk being hard to estimate and generally underestimated in fatter-than-expected tail cases, given the many manifestations of disorder over time. Exposure being any risk value above zero, and the primary concern for antifragility.
We might conclude from the above that due to the size and porosity of the input and output spaces, we remain exposed to harmful values and hence catastrophic failure, however many rules and safety guardrails we bake into prompts. Indeed many researchers conclude prompt injection is unsolvable in general, but may be ameliorated in practice with defense in depth.
Antifragile AI Architectural patterns
With that baseline established, let’s crack on with the Antifragile AI Architectural patterns. They are not mutually exclusive, and I’ve described the relationships between them.
The patterns are:
- Generate and select offline
- Reduce output dimensionality
- Small language models
- Generate and test online
- Durable core, ephemeral shell
- Constrain inputs
Generate and select offline
In this pattern we use generative AI to help us craft a fixed set of pre-approved responses. We generate a number of responses, run some test to select those that are desirable, and discard the rest. This pattern is useful if the cost of bad responses is catastrophic, because we can make sure no bad responses ever get to production, but we can still capture the great responses.
In presentation, these responses could then be templated and parameterised, combined, selected at random, etc, to give a wider response capability that gives a sense of variability or immediacy, and we save on inference-time costs to boot.
Pre-approved responses would be mapped either dynamically to unconstrained inputs (because at worst these responses would be neutral) or statically to a set of predefined inputs. “Whither GenAI?” you might ask of this architecture, but it’s still in play, just in offline mode.
This is another example of humans exercising optionality to capture beneficial variation.
Reduce output dimensionality
We can more easily limit the most egregious failure modes by reducing the output dimensionality, which can eliminate some failure modes altogether and make others easier to catch.
If the surface form of the output is low-dimensional, such as classifier labels, then we are effectively in traditional ML territory, but implemented with an LLM, but ideas from traditional ML still work.
However, if the surface form is to be higher-dimensional, like a text description or a raster data visualisation, then we can still collapse extraneous dimensions to zero.
A typical approach is to limit outputs to a Domain Specific Language (DSL), which can be tested for compliance and further constrained by structured business logic such as text-to-SQL with semantic layer or generating plots with highly-abstracted APIs such as Plotly or Bokeh.
This pattern may be considered to sit between offline and online generation, at the upper limit of templating, parameterisation and combination, and as an example of generate and test (partial test at least, when the output must compile or run against an API).
Small language models
Small Language Models are another method to reduce output dimensionality, by directly targeting the input/output space of LLMs, including with smaller, domain-specific training sets. In this case, we return closer to traditional ML, where we deliberately curate training data. As a result, we reduce the potential for certain catastrophic failures, but we also reduce the potential, previously undiscovered upside we can generate. This approach generally requires a high level of maturity, but that may change over time with improved tooling.
Otherwise in these patterns, we assume curation of training data to be beyond our control. That is, the LLMs we use for maximum potential upside are trained by a third party, and we have little visibility into what they are trained on, and hence what they are capable of reproducing.
Generate and test online
If, instead of manual inspection, we have some economical method of validating a correct answer or if we can reliably detect catastrophically harmful answers, we can take multiple shots at generating a right answer, and filter out any neutrals or harmful answers before responding to the user. Generate and test is an error correction protocol. It’s also an optimal response search strategy, as it can provide a simulation environment.
This works best if the test is deterministic, as we can guarantee no exposure to harmful responses. The test can also be non-deterministic, and provide some benefit of filtering more right answers from the rest, such as the LLM-as-a-Judge pattern. However, as above, a non-deterministic LLM test cannot entirely eliminate our exposure to harmful answers.
We may also iteratively refine the inputs to subsequent generation attempts using any error signals we can get from the test method, which we anticipate will increase the likelihood or quality of a right answer. This iterative approach becomes a form of reinforcement learning with the reward signal from the test. Code generation is well suited to this approach.
Generate and test online also increases inference costs to multiples of the original generation in the assurance of the response, especially when we iterate.
However, it is still an example of capturing upside while protecting against (catastrophic) downside.
Durable core, ephemeral shell
Like functional core, imperative shell, this pattern pushes components that are useful but somewhat problematic for reuse or maintenance to the edges. With a deterministic durable core, we can prevent catastrophic failures and explicitly limit our exposure, at least in regards to access to systems and other resources.
Simultaneously, the ephemeral shell can utilise all the capabilities of non-deterministic LLMs or agents to generate a variety of responses, possibly with multiple generate and test iterations, while leveraging protected resources from the core that provide proprietary differentiation.
As a sound bite, we might think about the durable core as the tools used by agents in the ephemeral shell. The core is open for extension by the shell, closed for modification.
The durable core can also expose interfaces that are consistent across multiple integrations (deterministic as well as non-deterministic), while still allowing more flexible interaction in the shell to capture upside from more scenarios, which may include one-off interactions. From earlier patterns, the durable core may include pre-approved responses, DSLs and their execution engines, and response validators.
The ephemeral shell contains components that are specialised and/or disposable. They may be hand-written, vibe-coded, spec-first, dynamically generated JIT by agentic solutions, etc. The point is they can’t fail catastrophically and they are not required to endure, but they can solve specific high-value problems. They may migrate into the core if they prove repeatedly useful.
Unmesh Joshi makes this point in What is Code?
In that sense, strong foundational code becomes even more important in the age of LLMs. Once the vocabulary of a system is well formed, coding becomes less about producing raw syntax and more about using a well-developed conceptual language to build reliable software.
This is also the pattern I describe in LLMs are lineage black holes, in regards to pushing LLMs as far as possible downstream in data analytics. The upstream data sources and transformations (data products) form the durable core for reliability and reuse in general, and can be made read-only for AI consumers, but AI-assistance can provide immense flexibility at the point of consumption.
I first used this pattern in my work on Helitronic Tool Studio in the early 2000s. Low-level parameterised standard mathematical and machining primitives were defined in the durable core, and users could then script extensions using arbitrary values, functions and higher-level logic to drive the core to produce custom tools including one-off specials. Many other Integrated Design Environments (IDEs) provide this type of scripting flexibility, such as Blender.
It’s also a pattern I describe in my DRY vs WRY analysis of reuse of LEGO® parts in sets, noting a power-law distribution of a few core durable components heavily reused across sets for basic functionality, and vastly larger halo of ephemeral parts customised to specific and short-lived set needs.
Again, this pattern allows valuable upside to be captured from the ephemeral shell, while the durable core protects against catastrophic downside.
Constrain inputs
We may significantly narrow the possible inputs, which also has the effect of limiting the range of outputs. As above, neither a deny list nor a non-deterministic LLM input filter can guarantee against exposure to harmful inputs. The only guarantees are obtained with allow lists or deterministic input filters.
From the perspective of the ephemeral shell, constraining inputs may be one role of the durable core. However, we still retain variation in outputs where desirable for user experience, or even necessary to search for a good solution, to capture more upside.
Apple Intelligence Writing Tools show an example of this, at least in the limited set of functions to transform writing that are offered, if not the writing itself, which we presume is not catastrophically bad for the writer!
Constraining inputs can also protect against catastrophic failure while allowing for upside generation.
Evolving these patterns
Evolutionary improvement over time is another characteristic of antifragile systems. As noted above and in my earlier post, humans exercising optionality based on signals from deployed software is a selection mechanism. To this, we can now add LLM-based-agents, or hybrid human-machine improvement selection systems.
User: Generate another pattern here in the style of safetydave.net
That’s all I have for now, but I’ll reserve the right to add to the patterns if anything else occurs to me. I’d welcome any feedback or any ideas you have for more patterns.
(And seriously, no AI used in writing on safetydave.net, as that that would defeat the objective, though my copyright content is non-consensually included in training data sets.)
Acknowledgements
Thanks Ned Letcher for elaborating the Reduce Output Dimensionality pattern and examples, and thanks to Minna Yao for convincing me to include Small Language Models.